mlpy.learners.offline.irl.ApprenticeshipLearner.learn¶
-
ApprenticeshipLearner.learn()[source]¶ Learn the optimal policy via apprenticeship learning.
The apprenticeship learning algorithm for finding a policy
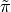 ,
that induces feature expectations
,
that induces feature expectations 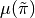 close to
close to 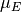 is as follows:
is as follows:- Randomly pick some policy
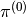 , compute (or approximate via Monte Carlo)
, compute (or approximate via Monte Carlo)
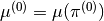 , and set
, and set 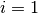 .
. - Compute
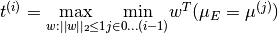 ,
and let
,
and let 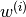 be the value of
be the value of 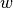 that attains this maximum. This can be achieved
by either the max-margin method or by the projection method.
that attains this maximum. This can be achieved
by either the max-margin method or by the projection method. - If
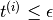 , then terminate.
, then terminate. - Using the RL algorithm, compute the optimal policy
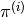 for the MDP using rewards
for the MDP using rewards
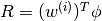 .
. - Compute (or estimate)
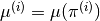 .
. - Set
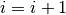 , and go back to step 2.
, and go back to step 2.
- Randomly pick some policy