mlpy.mdp.discrete.DecisionTreeModel¶
-
class
mlpy.mdp.discrete.DecisionTreeModel(actions=None, explorer_type=None, use_reward_trees=None, *args, **kwargs)[source]¶ Bases:
mlpy.mdp.discrete.DiscreteModelThe MDP model for discrete states and actions realized with decision trees.
The MDP model with decision trees is implemented as described by Todd Hester and Peter Stone [R4]. Transitions are learned for each feature; i.e. there is a decision tree for each state feature, and the predictions
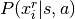 for the
for the nstate features are combined to create a prediction of probabilities of the relative change of the state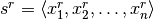 by
calculating:
by
calculating: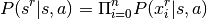
Optionally, the reward can also be learned by generating a decision tree for it.
The MDP model with decision trees can optionally specify an RMax based exploration model to drive exploration of unseen states.
Parameters: actions : list[Action] | dict[State, list[Action]
The available actions. If not given, the actions are read from the Action description.
explorer_type : str
The type of exploration policy to perform. Valid explorer types:
- unvisitedbonusexplorer:
In unvisited-bonus exploration mode, if a state is experienced that has not been seen before the decision trees are considered to have changed and thus are being updated, otherwise, the decision trees are only considered to have changed based on the C45Tree algorithm.
- leastvisitedbonusexplorer:
In least-visited-bonus exploration mode, the states that have been visited the least are given a bonus of RMax. A
LeastVisitedBonusExplorerinstance is create.- unknownbonusexplorer:
In unknown-bonus exploration mode states for which the decision tree was unable to predict a reward are considered unknown and are given a bonus of RMax. A
UnknownBonusExplorerinstance is create.
use_reward_trees : bool
If True, decision trees are used for the rewards model, otherwise a standard reward function is used.
args: tuple
Positional parameters passed to the model explorer.
kwargs: dict
Non-positional parameters passed to the model explorer.
Other Parameters: explorer_params : dict
Parameters specific to the given exploration type.
Raises: ValueError
If explorer type is not valid.
Notes
A C4.5 algorithm is used to generate the decision trees. The implementation of the algorithm that was improved to make the algorithm incremental. This is realized by checking at each node whether the new experience changes the optimal split and only rebuilds the the tree from that node if it does.
References
[R4] (1, 2) Hester, Todd, and Peter Stone. “Generalized model learning for reinforcement learning in factored domains.” Proceedings of The 8th International Conference on Autonomous Agents and Multiagent Systems-Volume 2. International Foundation for Autonomous Agents and Multiagent Systems, 2009. Attributes
midThe module’s unique identifier. statespaceCollection of states and their state-action information. Methods
activate_exploration()Turn the explorer on. add_state(state)Add a new state to the statespace. deactivate_exploration()Turn the explorer off. fit(obs, actions[, rewards])Fit the model to the trajectory data. get_actions([state])Retrieve the available actions for the given state. load(filename)Load the state of the module from file. predict_proba(state, action)Predict the probability distribution. print_rewards()Print the state rewards for debugging purposes. print_transitions()Print the state transitions for debugging purposes. sample([state, action])Sample from the probability distribution. save(filename)Save the current state of the module to file. update([experience])Update the model with the agent’s experience.