mlpy.learners.offline.irl.ApprenticeshipLearner¶
-
class
mlpy.learners.offline.irl.ApprenticeshipLearner(obs, planner, method=None, max_iter=None, thresh=None, gamma=None, nsamples=None, max_steps=None, filename=None, **kwargs)[source]¶ Bases:
mlpy.learners.offline.IOfflineLearnerThe apprenticeship learner.
The apprenticeship learner is an inverse reinforcement learner, a method introduced by Abbeel and Ng [R2] which strives to imitate the demonstrations given by an expert.
Parameters: obs : array_like, shape (n, nfeatures, ni)
List of trajectories provided by demonstrator, which the learner is trying to emulate, where n is the number of sequences, ni is the length of the i_th demonstration, and each demonstration has nfeatures features.
planner : IPlanner
The planner to use to determine the best action.
method : {‘projection’, ‘maxmargin’}, optional
The IRL method to employ. Default is projection.
max_iter : int, optional
The maximum number of iteration after which learning will be terminated. It is assumed that a policy close enough to the experts demonstrations was found. Default is inf.
thresh : float, optional
The learning is considered having converged to the demonstrations once the threshold has been reach. Default is eps.
gamma : float, optional
The discount factor. Default is 0.9.
nsamples : int, optional
The number of samples taken during Monte Carlo sampling. Default is 100.
max_steps : int, optional
The maximum number of steps in an iteration (during MonteCarlo sampling). Default is 100.
filename : str, optional
The name of the file to save the learner state to after each iteration. If None is given, the learner state is not saved. Default is None.
Other Parameters: mix_policies : bool
Whether to create a new policy by mixing from policies seen so far or by considering the best valued action. Default is False.
rescale : bool
If set to True, the feature expectations are rescaled to be between 0 and 1. Default is False.
visualize : bool
Visualize each iteration of the IRL step if set to True. Default is False.
See also
Notes
Method maxmargin using a QP solver to solve the following equation:
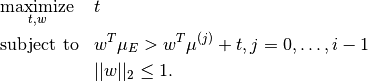
and mixing policies is realized by solving the quadratic problem:
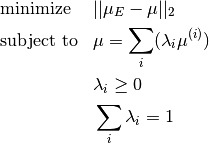
The QP solver used for the implementation is the IBM ILOG CPLEX Optimizer which requires a separate license. If you are unable to obtain a license, the ‘projection’ method can be used instead.
References
[R2] (1, 2) Abbeel, Pieter, and Andrew Y. Ng. “Apprenticeship learning via inverse reinforcement learning.” Proceedings of the twenty-first international conference on Machine learning. ACM, 2004. Attributes
midThe module’s unique identifier. typeMethods
choose_action(state)Choose the next action end()End the episode. init()Initialize the apprenticeship learner. learn()Learn the optimal policy via apprenticeship learning. load(filename)Load the state of the module from file. save(filename)Save the current state of the module to file. start()Start an episode. step(experience)Execute learning specific updates.